Programs and Memory
Overview
When a program is run, the variables in the program are stored in the computers memory. As it turns out, computers don't just have one flat area for storing variables. Instead, memory is dived sharply into the stack and the heap. Today we will look at these areas of memory and how they work with regards to the programs we run.
It may seem like the way variables are stored in memory is a technical detail we won't need to actually write programs, but understanding where the variables and objects we create go is crucial to understanding how programs really work. Moreover, lots of the programming errors you may run into come from not dealing with memory correctly.
The Stack
The stack is used to store all of the variables used by the methods of our programs. When we are inside of a method, the parameters into the method and the local variables of the method are stored on the stack.
Each method gets its own area of the stack which is called a stack frame. When a method is called, it gets a stack frame added to the top of the stack. When a method returns, its stack frame is removed off of the top of the stack.
For example, let's say we have the following program:
public class Methods {
public static double multiply(double a, double b) {
double result = a * b;
return result;
}
public static double addTip(double amount, int percent) {
double pct = percent / 100.0;
double total = multiply(amount, 1.0 + pct);
return total;
}
public static void main(String args[]) {
double cost = 34.17;
double total = addTip(cost, 15);
System.out.printf("Total = %.2f\n", total);
}
}
When we first begin executing this program, we will begin in main. At that point, a stack frame for main is pushed on the stack:

The parameter args would have a value, but let's ignore that for now.
Then, as the code runs, it does the assignment of cost. Primitive variables
like this have their values stored directly in stack memory:

The code then calls the addTip method. This pushes a new stack
frame onto the stack. The values of the parameters are set in the stack before
the method begins to run:

The next thing that happens in the program is that addTip assigns the pct variable:

We then will call the multiply method. This adds another
stack frame to the stack for the new method. Again, the parameter values
are passed in:
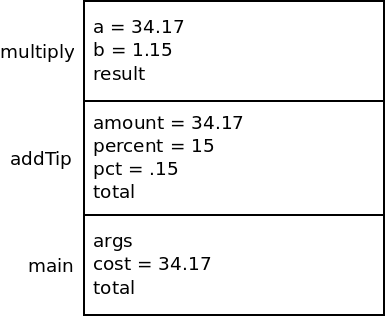
Now, multiply will set its result variable to the product of
its two parameters:
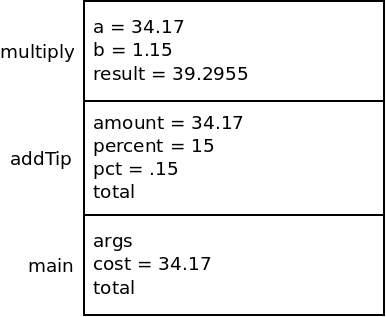
The next thing that multiply does is to return this value from the method. A few things will happen now. The stack frame for multiply will be removed. The value it returns will be sent back to the method which called it (addTip in this case) and be set into a variable. Then, we continue where we left off in that method:
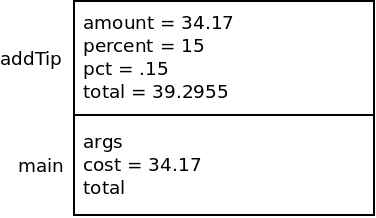
Now addTip will also return the total variable back to main:

Next, we will call the System.out.printf method. The benefit of this
method is it lets us add formatting to the output so we can print two
decimal places. This is also a method, and so gets pushed onto the stack
when we call it. This method is sort of a "black box" to us. We don't
need to know its parameter names or local variables. Still, we should
know it has a stack frame:
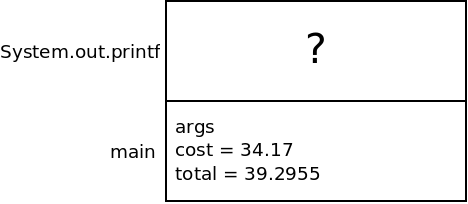
We then return from printf:

And then finally main ends, which removes its stack frame as well. At that point the stack is empty and the program is over.
The Heap
We'll now look at the other primary section of memory which is the
heap. The heap is used for storing all objects. Whenever you create
an object with new, that object lives on the heap.
Unlike the stack, the heap is not especially structured. Every method doesn't get its own heap space. Instead, whenever we need to use new, the Java VM finds some space on the heap (that's big enough for what we need) and gives it to us.
For instance, let's say we make a Scanner object, in the main method:
public static void main(String args[]) {
Scanner in = new Scanner(System.in);
// ...
}
This code will create space on the heap for our object, run the Scanner constructor, and then give us back a reference to that object. A "reference" is the memory address of where the object is in the heap.
So we tend to think of the scanner in the code above as just one thing.
But it's actually two: we have a reference to the object
which is called in and lives on the stack. Then we have the
actual Scanner object itself which is stored in the heap:
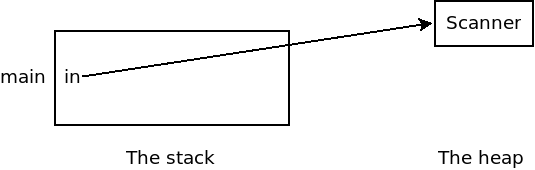
In this figure, we've drawn in pointing to the scanner
on the heap. This shows that in refers to that object. For this reason,
references are also called "pointers" as in the common NullPointerException.
What's really happening is that the address of the scanner on the heap
is stored in the variable called in. For instance, if
the object is stored at memory location 12000, then that number would
literally be stored in our variable in.
In Java, the heap only stores objects. The stack only stores primitives and references to objects.
Objects on the heap are anonymous. The Scanner object in the example above does not have a name. Reference variables (like in) have names, but objects do not.
We can point multiple reference variables to the same object in memory. Let's say we do this:
public static void main(String args[]) {
Scanner in = new Scanner(System.in);
Scanner in2 = in;
// ...
}
Now both in and in2 have the same address
stored in them. We could draw that like this:
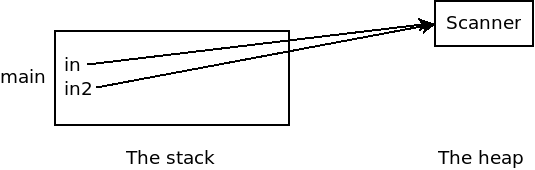
Misunderstanding the difference between a reference and an object, can lead to lots of programming mistakes.
For example, if we have code like this:
public static void main(String args[]) {
ArrayList<String> list;
list.add("Joe");
}
What is the problem?