Graphs
Overview
A graph is a data structure that consists of a number of nodes (or vertices) and a number of edges. An edge is a connection between two nodes. Nodes are used to represent objects and the edges represent some kind of relationship between them. Below is a diagram of a graph with 6 nodes and 6 edges:
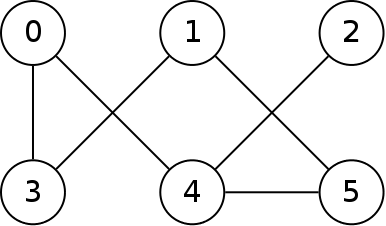
Graphs are a very useful data structure as they can be used to represent many different kinds of relationships between data. There are many graph algorithms that operate on graphs, of which we will only cover a small number.
Graph Applications
Graphs are used to represent many relationships between data. A few examples:
- Computer networks.
- Transportation.
- Compilers.
- Scheduling tasks.
- Matching problems.
- Website links.
- 3D graphics.
- Relationships between information.
Types of Graphs
A directed graph is one in which the edges have a specific direction. It is possible to have two edges connecting two nodes: one in one direction and another in the other. Below is a diagram of a directed graph:
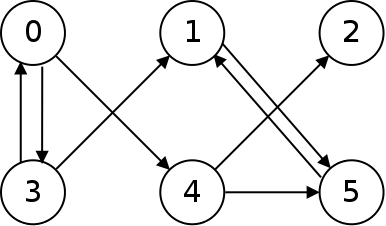
A weighted graph is one in which the edges have some number, called a weight, associated with them. One example where weighted graphs are used is to represent paths between different locations, where the distances between are given as weights. Below is a diagram of a weighted graph:
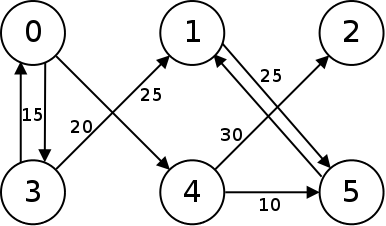
A connected graph is one in which there is a path from any one node to every other. The graph above is not connected because there is no way to get from node 2 to node 3. Below is a diagram of a connected graph:
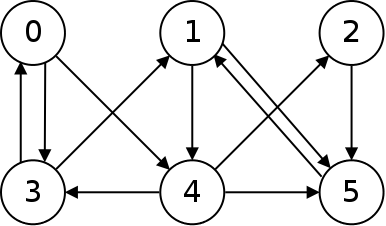
A complete graph is one in which there is an edge between every pair of nodes in the graph. Below is an undirected complete graph with five nodes.
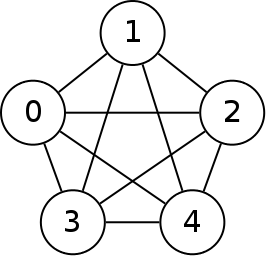
For a directed graph to be considered complete, it would need two edges for every pair of nodes, one in each direction.
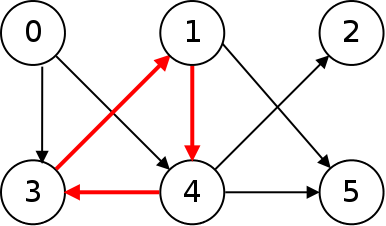
An acyclic graph is one in which there are no cycles. A cycle is a set of edges that can take you from a given node back to that node. The following graph has a cycle which is shown in red:
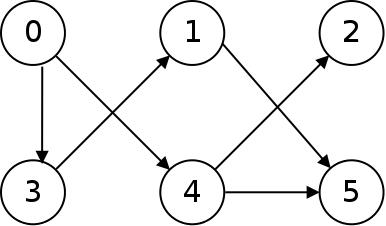
Because the following graph has no cycles, it is called acyclic:
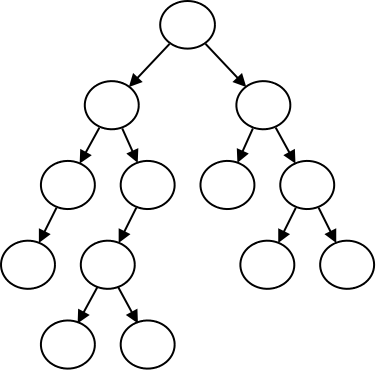
A tree is a special type of directed graph which is acyclic and has the additional rules that one node (the root) has no edges entering it, and every other node has exactly one edge entering it:
Adjacency Matrix
One way to store a graph in a computer program is to use an adjacency matrix which is a two dimensional array. The matrix is $N \times N$ where $N$ is the number of nodes.
At each location in the matrix is stored the weight of the edge that connects those two nodes if there is one:
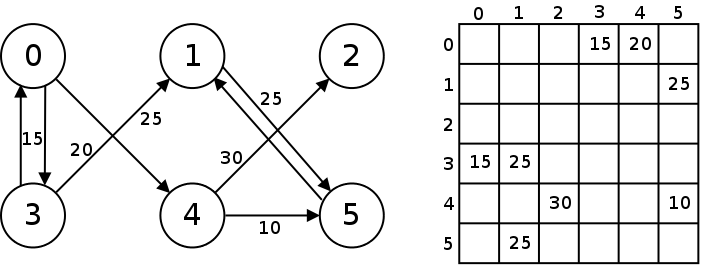
For the locations in the adjacency matrix where there is no edge, we can store a sentinel value such as 0 or -1. In most applications weights that are zero or less would not be used (such as for distances).
To implement this, we can make a Graph class with a 2D array of integers:
class Graph {
private int[][] matrix;
int size;
// start with no edges at all
public Graph(int size) {
this.size = size;
matrix = new int[size][size];
for(int i = 0; i < size; i++) {
for(int j = 0; j < size; j++) {
matrix[i][j] = 0;
}
}
}
Here the constructor allocates space in the matrix, and sets all the cells to 0.
We can easily create methods to insert and remove edges, and to return the cost of an edge:
// insert an edge
public void insertEdge(int from, int to, int cost) {
matrix[from][to] = cost;
}
// remove an edge
public void remove(int from, int to) {
matrix[from][to] = 0;
}
// return the cost of an edge or 0 for none
public int getCost(int from, int to) {
return matrix[from][to];
}
If 0 cost is allowed, then -1 can be used instead.
For unweighted graphs, the values stored in the matrix can just be true or false.
The full example is in AdjacencyMatrix.java.
Incidence List
An alternative way to implement a graph is with an incidence list. In an incidence list, we store a linked list for each node that contains the edges for that node. Each element in the linked list represents one edge in the graph, and stores the target node and the weight (if any).
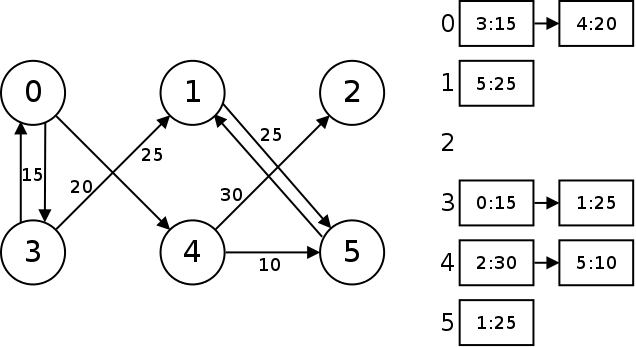
In order to implement this idea, we will use Java's built-in linked list class. Next, we will need to create a class to represent an edge of the graph. Each edge will contain the node it connects to and the weight (assuming a weighted graph):
class Graph {
// a class for storing an edge of the graph
private class Edge {
public int to;
public int cost;
public Edge(int to, int cost) {
this.to = to;
this.cost = cost;
}
// this is so we can search for edges by destination
public boolean equals(Object other) {
Edge otherEdge = (Edge) other;
return to == otherEdge.to;
}
}
The Edge class also provides a constructor, and an equal method. The latter is provided so that we can search the list for edges.
Next we can make an array of linked lists of edges. Each element in this array is a node of the graph, and contains the list of edges leaving this node:
// an array of linked lists, each list holds the edges out of that node
private LinkedList<Edge>[] nodes;
// construct an empty graph of a given size
public Graph(int size) {
// becasue this is a generic array, we need to cast
nodes = (LinkedList<Edge>[]) new LinkedList[size];
for (int i = 0; i < size; i++) {
nodes[i] = new LinkedList<Edge>();
}
}
In order to provide methods to add, remove, and search for edges, we can simply call on the appropriate linked list methods:
// insert an edge
public void insert(int from, int to, int cost) {
nodes[from].add(new Edge(to, cost));
}
// remove an edge
public void remove(int from, int to) {
nodes[from].remove(new Edge(to, -1));
}
// return the cost of an edge or 0 for none
public int getCost(int from, int to) {
// search the linked list for this edge
int index = nodes[from].indexOf(new Edge(to, -1));
// if -1, return 0
// else return the cost of that edge
if (index == -1) {
return 0;
} else {
return nodes[from].get(index).cost;
}
}
The full example is in IncidenceList.java.
Adjacency Matrix vs. Incidence List
Adjacency matrices and incidence lists provide different benefits. Here are some of the pros and cons:
- Adjacency matrices are a little simpler to implement
- Adjacency matrices are faster to remove and search for edges
- Incidence lists take less memory for "sparse" graphs
- Incidence lists take less time to loop through for sparse graphs, but a little more for dense ones.
Overall, adjacency matrices are a better choice when the graph can become dense (having many connections). Incidence lists are better when the graphs will usually be sparse (having few connections).
Storing Data in the Graph
In the examples above, we have the nodes of a graph represented with integers from 0 to $N$ - 1. We then use either an adjacency matrix or incidence list to store the edges to other nodes. The examples above don't actually store any data in the graph nodes though.
For an incidence list, we would have each node store the data for each node and the list of edges coming out of it together. We would then create a list or array of nodes to represent the graph.
To do that for an adjacency matrix, we would store a 1-dimensional array where each element stores the data associated with each node. We would still have the 2-dimensional array with the edges.
An example of a generic Graph class which stores values in each node, and stores the edge information in an adjacency matrix is available in Graph.java.