As we saw last time, routers forward packets based on a forwarding table. This table tells them which interface to send packets out on based on the prefix of their IP address.
The next question we need to address is how does this table get created in the first place?
In the network layer there are two main things that happen: routing and forwarding. Forwarding is sending a packet along to the next hop, and is done quickly. Routing is the global decision of how to get a packet from a starting point to an ending point.
We have seen how forwarding is done with tables. Routing is the process of building the forwarding tables.
Routing views the network as graphs. The hosts (including routers as well as computers) are nodes in the graph and the links between them are edges. Each edge has some cost associated with it. This cost can be the distance of the link, the speed of the link or some combination.
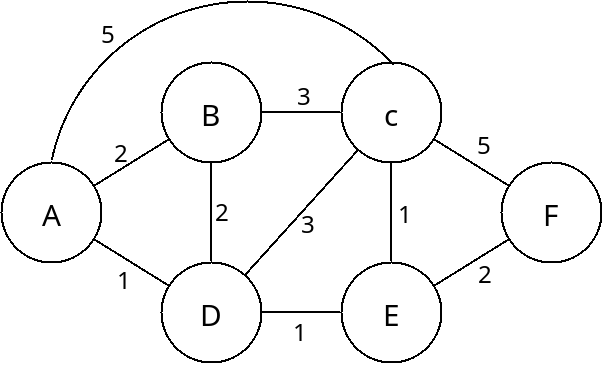
Viewing a network as a graph
The question of how to route a packet from one host to another then becomes a graph problem. We should simply find the route with the least total cost.
In the graph above, what route should we use between A and C?
Routing algorithms can be divided into centralized and distributed ones.
In a centralized algorithm, we have all of the information for the entire network in one place. One machine must know all about which nodes connect to which other ones, as well as all of the costs. This machine can then compute the optimal routes between any two pairs of nodes.
In a distributed algorithm, we do not need to have all of the information on the entire network stored in one place. No one node needs to know the entire layout of the network or the costs between all different nodes. Instead, they each start with knowledge of their immediate neighbors only. They exchange information as the algorithm progresses and arrive at an overall solution iteratively.
We can also distinguish between static and dynamic routing. In a static algorithm, the routing changes relatively slowly. For example, only when someone changes a cost and reruns the algorithm. In a dynamic algorithm, the routing can change as the network changes without having to be re-run explicitly.
The Internet uses both centralized, static algorithms as well as distributed dynamic ones, in different situations.
In truth, the Internet is not just a "flat" graph with all nodes in the entire Internet treated the same way. There are two main reasons for this:
For this reason, the Internet is made up of many "Autonomous Systems" which are groups of routers under the control of one organization. In this way, routing in the Internet is sort of a hierarchical network of networks:
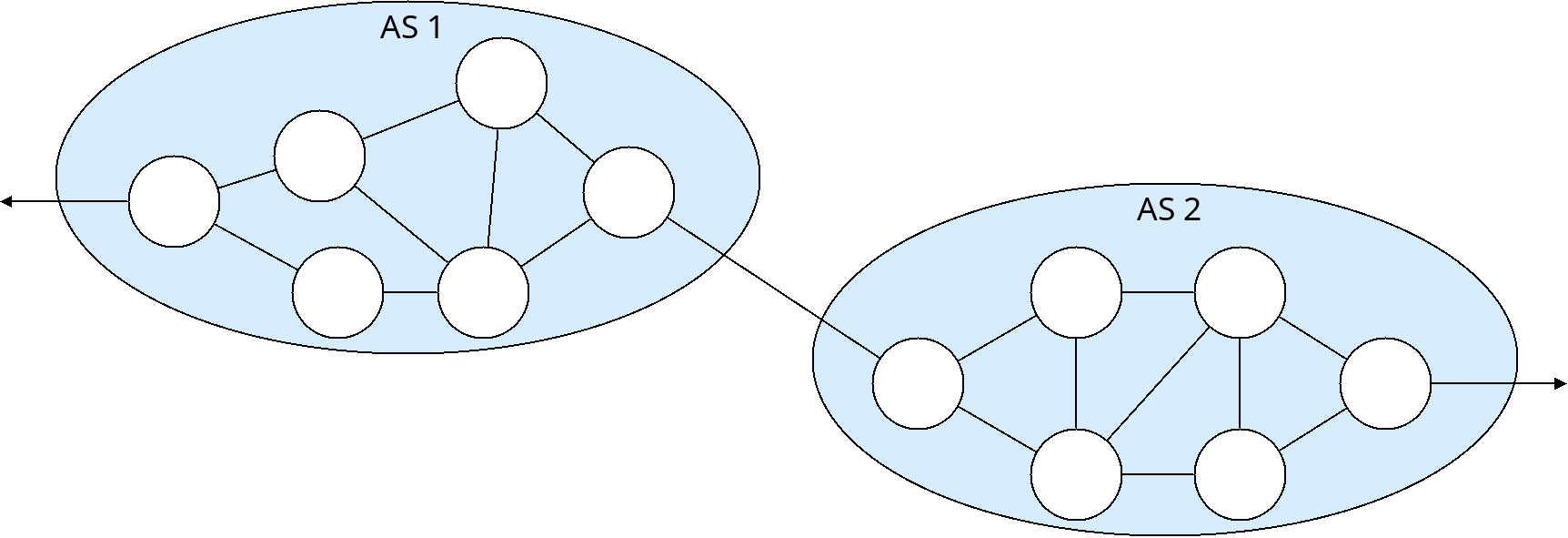
Two Autonomous Systems
Each autonomous system (AS) handles routing inside of its network internally. Outside of the AS, nodes do not generally know how routing is done inside of the AS, or the network topology or cost of the graph inside of the AS. The routers that connect an AS to routers in the outside world are called "Gateways".
Routing algorithm can thus be used either within an AS, or between different AS's. Within an AS, an organization can route however it wants to, it is autonomous. Routing between AS's requires fixed standards.
A helpful analogy is to think of the AS's like nations. Each nation is autonomous and can set its own laws within the nation. However, there are also international laws which govern the ways nations relate to one another.
Organizations are free to route however they want within an AS. Typically they use centralized routing, because the entire graph of the AS is known. This allows computing the optimal routing within the AS easily.
There are several protocols for routing within an AS, many of which are proprietary. However one common one is the Open Shortest Path First (OSPF) protocol which is outlined below:
Dijkstra's algorithm is used as part of OSPF (and many other routing algorithms) for actually finding the shortest paths. The algorithm is given below:
What does Dijkstra's algorithm give us for the routing from node A for this graph:
There is one routing algorithm for routing between AS's, which is the Border Gateway Protocol (BGP). "Border" here refers to the areas between different autonomous systems.
BGP is universal for this purpose because there is no centralized authority for routing between AS's, so all routers must agree on the protocol to use. BGP is a distributed, dynamic protocol.
BGP is a very complex topic, below is just a rough sketch of how it works:
Routing is the problem of giving individual routers the correct forwarding information to allow packets to travel across the entire Internet from their source to their destination.
If a packet needs to get from a laptop on a home network in Virginia to a web server in a data center in Europe, it must likely travel through many routers along the way. The Internet is broken down into autonomous systems based on ISPs. These ISPs route packets within their AS how they want, usually with a centralized algorithm. The packets find their way between AS's using the distributed BGP protocol.
The network layer does its best to deliver packets from the source to the intended destination. However, packets can still get dropped, or arrive in a different order than they were sent. The net layer over the network layer is the transport layer, which will address these issues.
Copyright © 2025 Ian Finlayson | Licensed under a Creative Commons BY-NC-SA 4.0 License.