To gain experience writing parallel programs, and learn about genetic approximation algorithms.
The bin packing problem is a well-known optimization problem. In this problem, you have $N$ items of different sizes. You want to pack the items into bins, using the fewest bins possible.
For instance, imagine we have the following items:
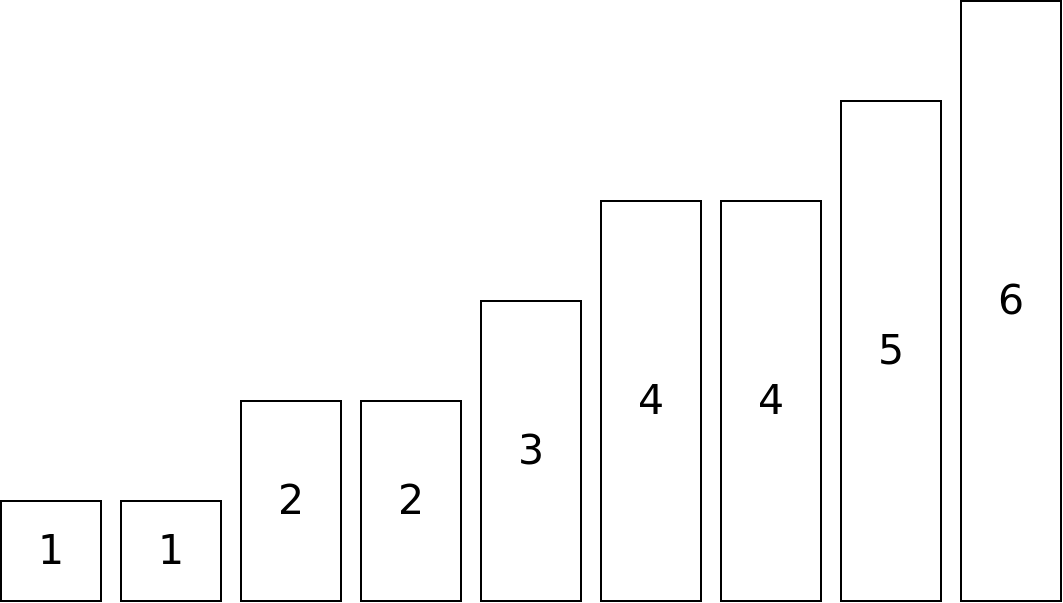
We want to pack these items into bins such that we use as few bins as possible. Let's say the bin size is 7. That means that the total size of the items in any one bin must be 7 or less.
A simple greedy solution to the problem is to just take the items, one by one, and put them into a bin they will fit in. If they don't fit in any, we start a new bin. If we follow this algorithm for the items above, we will use 5 bins:
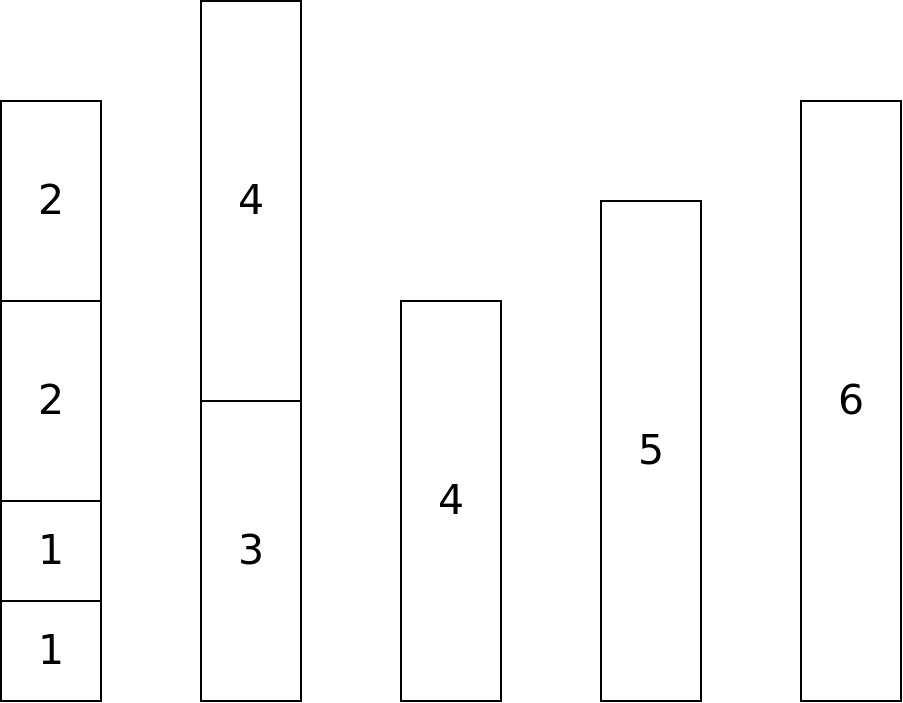
However in this case, there is a better solution using only 4 bins:
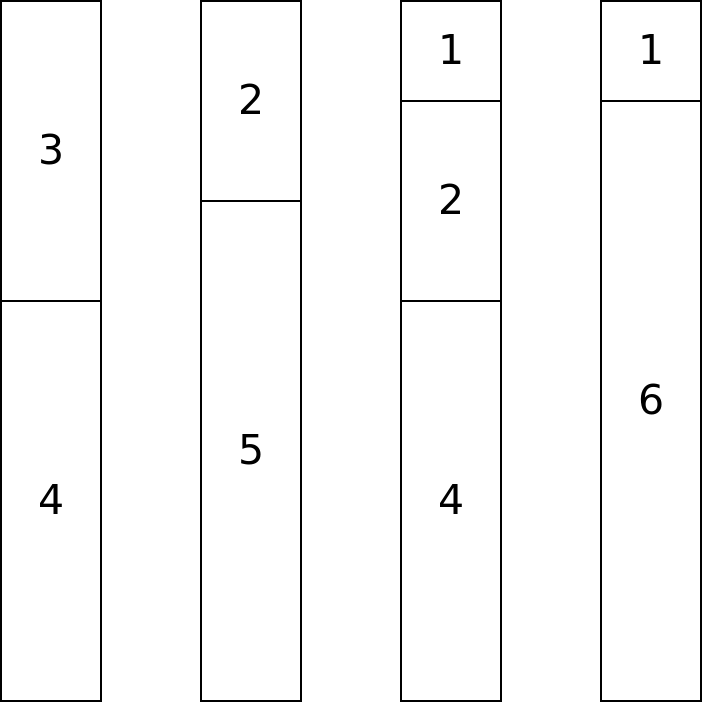
Bin packing is a very hard, $NP$-Complete problem. One way of viewing the solution to the problem is to find the ordering of the $N$ items, in which the greedy solution produces the correct result. For example, if we use that method in the items in the order:
4, 3, 5, 2, 4, 2, 1, 6, 1
Then we will arrive at the optimal solution. The problem is that with $N$ items, there are $N!$ many orderings. The brute force solution, then, is to try to pack the items in all $N!$ orders, and see which one was best. This is not feasible for large values of $N$. For example, when $N = 100$, $N! = 9.33 \times 10^{157}$. For comparison, the number of atoms in the observable universe is estimated to be about $10^{80}$.
Rather than find an exact solution to bin packing, what most do is find an approximate solution. An approximation algorithm is one which finds a "good enough" solution to a problem which may or may not be the best one possible.
There is a type of approximation algorithm that can be applied to a wide number of optimization problems called genetic algorithms. A genetic algorithm borrows concepts from biological evolution to iteratively improve upon a set of solutions.
In a genetic algorithm, we maintain a population of solutions. In each step of the algorithm, we determine the fitness of each member of the population - how likely it is to survive. Then the members of the population who are least fit are eliminated. Then new members are created by modifying the most fit members of the population.
If we use a genetic algorithm to approximate bin packing, the population could consist of orderings of the items. The fitness will be the number of bins used to store those items using the greedy algorithm. The most fit members of the population which use the fewest bins.
When the algorithm starts, the population consists of entirely random sequences. Sequences which use more bins will be removed. The new members of the population can be created by randomly mutating the sequences with the fewest bins: randomly changing the order of some of the items. Sometimes, entirely new random sequences can be created which represent new species - this can avoid the process being stuck in local minimums.
The exact details are left up to you:
When the genetic algorithm finishes, the most fit member of the population is given as the approximate solution.
Genetic algorithms are good candidates for being parallelized. There are multiple approaches to this:
Which approach you take is up to you.
Your job is to use a parallel genetic algorithm, using either Pthreads, OpenMP, or MPI, to solve instances of the bin packing problem, using some variant of the parallel genetic algorithm described above.
Your program should read in the input file as the first and only input to the program.
The first line of the input file gives the size of each bin. For each test case, there is only 1 size of bin to pack, but each test case has a different size bin.
The second line gives the number of items, $N$. Following that are $N$ lines, each giving the size of one item to be packed.
There are three test cases that you can work with:
| Test Case | Items | Optimal Bins |
|---|---|---|
| micro.txt | 8 | 3 |
| small.txt | 29 | 7 |
| large.txt | 150 | ??? |
The first test case has only 8 items, which have $8! = 40320$ different orderings. The optimal packing is tight - each bin is totally filled to capacity. The second test case has 29 items which can fit into 7 bins. There are many more possible packings of these items, but there is some extra space in the packing. Your program should be able to find the optimal solution for these two test cases.
The third test case has 150 items, which have a colossal number of possible packings. I don't know the optimal number of bins to pack these numbers. Finding an exact solution to this instance of the problem would take an inordinate amount of time on our computer systems. Instead, we'll try to find the best solution we can using the genetic algorithm. Note that the number of bins can't be less than 52, due to the total weight of the items - but the actual minimum is likely a bit higher than that.
Your program should output the best packing you found along with the total number of bins. The output should include which items go in which bins, the size of each bin, along with the total bins used. Below is an example (for the micro test case):
$ ./pack micro.txt Bin 1: 5, 9, 11 (sum = 25) Bin 2: 15, 10 (sum = 25) Bin 3: 6, 11, 8 (sum = 25) Total weight is 75. Packed into 3 bins.
The student who finds the best approximation for the largest test case will have a 25% bonus added to their grade for this assignment (e.g. they could get a 125%). The student with the second best approximation will have a 10% bonus.
Below are some ideas for how to go about writing the program, which you do not have to follow:
In addition to your code, you should include a brief description of your program. This can be a separate document or just the message of an email. The description should include:
Submit the source code and the document to Canvas.
Copyright © 2024 Ian Finlayson | Licensed under a Creative Commons BY-NC-SA 4.0 License.